이전 글에서는 hover를 위한 reward와 termination 조건을 정리했다. 이제 남은 일은 이 조각들을 하나의 강화학습 환경(environment)으로 묶는 것이다. 그래야 PPO나 SAC 같은 알고리즘이 HoverPilot을 일반적인 Gymnasium 환경처럼 다룰 수 있다.
왜 Gymnasium인가
강화학습 프로젝트에서 알고리즘보다 먼저 정리해야 하는 것은 환경 인터페이스다. 아무리 state, action, reward를 잘 정의해도, 학습 코드가 기대하는 형태로 감싸지 못하면 재사용도 어렵고 실험도 번거로워진다.
Gymnasium은 그 문제를 아주 단순한 두 함수로 정리한다.
reset()은 episode(에피소드) 시작 상태를 반환한다step(action)은 행동 적용 후 다음 상태, reward, 종료 여부를 반환한다
겉보기에는 단순하지만, HoverPilot 입장에서는 이 인터페이스가 중요하다. RealFlight Link와 직접 대화하는 복잡성을 환경 안으로 밀어 넣고, 바깥에서는 표준 RL 환경처럼 보이게 만드는 경계면이 되기 때문이다.
환경의 역할
HoverPilot 환경은 단순히 RealFlight 상태를 전달하는 래퍼가 아니다. 실제로는 아래의 역할을 한곳에 모은다.
- Gymnasium action을 RealFlight control input으로 변환한다
- RealFlight Link에서 최신 state를 읽어 observation으로 압축한다
- reward와 termination을 계산한다
- trainer reset 이후 다음 에피소드가 시작될 수 있는 시점을 판단한다
이 구조를 그림으로 보면 더 직관적이다.
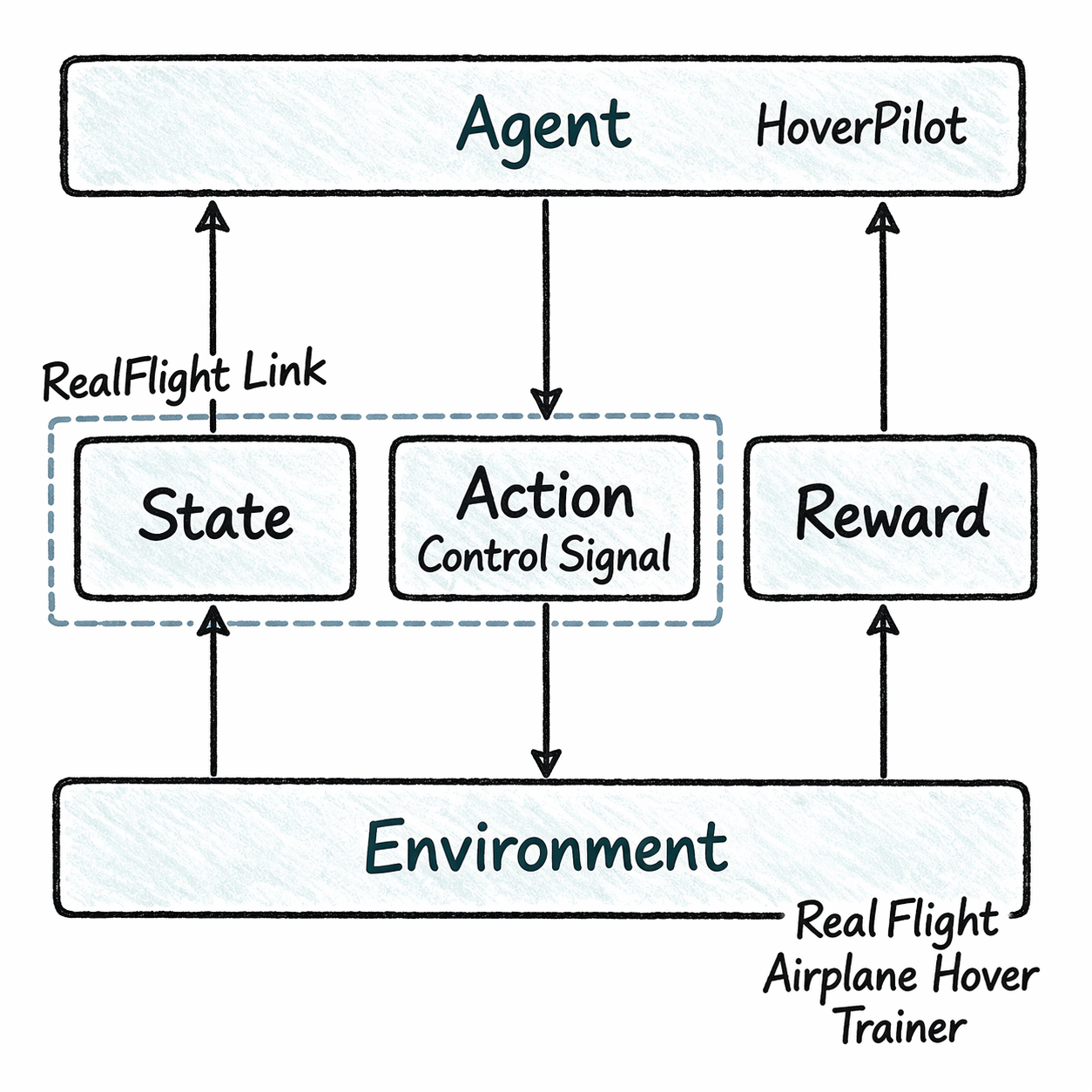
정리하면 이 네 가지 역할이 합쳐져, 시뮬레이터와 학습 루프 사이의 번역기이자 조정자 역할을 한다.
Action과 Observation
환경 바깥에서 보이는 action은 길이 4의 벡터다. 순서는 다음과 같다.
- aileron
- elevator
- throttle
- rudder
이 네 값은 Gymnasium 쪽에서는 [-1, 1] 또는 [0, 1] 범위로 다루고, 내부에서 RFControlAction으로 변환되어 RealFlight Link로 전달된다. 실제 구현에서도 action 공간을 이렇게 정의한다.
self.action_space = spaces.Box(
low=np.asarray([-1.0, -1.0, 0.0, -1.0], dtype=np.float32),
high=np.asarray([1.0, 1.0, 1.0, 1.0], dtype=np.float32),
dtype=np.float32,
)
observation은 hover 유지에 직접 관련된 값들만 추려서 12차원 벡터로 구성했다.
- position:
x,y,altitude - attitude:
roll,inclination,azimuth - velocity:
u,v,w - angular rates:
pitch_rate,roll_rate,yaw_rate
코드에서는 state를 이런 식으로 observation으로 압축한다.
def state_to_observation(state: FlightAxisState) -> np.ndarray:
return np.asarray(
[
state.m_aircraftPositionX_MTR,
state.m_aircraftPositionY_MTR,
state.m_altitudeAGL_MTR,
...,
state.m_yawRate_DEGpSEC,
],
dtype=np.float32,
)
모든 telemetry를 다 넣지 않고 hover에 직접 필요한 정보만 먼저 고른 이유는 간단하다. 첫 번째 환경은 가능한 한 작고 해석 가능해야 reward 튜닝과 학습 문제를 분리해서 보기 쉽기 때문이다.
reset()이 단순하지 않은 이유
Gymnasium의 reset()은 이름만 보면 단순해 보인다. 하지만 RealFlight Trainer에서는 에피소드가 끝난 직후 바로 다음 학습을 시작할 수 없는 경우가 있다.
- 에피소드 종료 후 기체가 이미 파손된 상태일 수 있다
- trainer가 아직 재배치(reposition)되기 전일 수 있다
- reset 직후 state가 잠시 비정상적으로 보일 수 있다
- 충돌 후 low altitude 상태나 정지 상태가 잠시 남아 있을 수 있다
처음에는 이 문제를 비교적 단순하게 처리할 수 있을 거라고 생각했다. 에피소드가 끝나면 실제로는 비행기가 파손되고, 엔진이 꺼지며, 잔해가 바닥에 떨어져 있기 때문이다. 그래서 m_hasLostComponents, m_anEngineIsRunning, m_isTouchingGround 같은 값을 보면 학습 종료 시점과 다음 에피소드 시작 시점을 구분할 수 있을 것이라고 예상했다.
하지만 실제로는 그렇지 않았다. 이 값들은 Trainer 모드에서 기대한 의미로 갱신되지 않았고, 실험 중에는 거의 항상 0만 반환했다. 즉 “부품이 떨어졌는가”, “엔진이 꺼졌는가”, “지면에 닿았는가” 같은 신호를 그대로 믿고 에피소드 lifecycle(수명주기)을 판단할 수 없었다.
결국 reset 로직은 명시적인 종료 플래그에 의존하는 대신, 여러 상태를 조합한 휴리스틱으로 구성할 수밖에 없었다. 예를 들어 위치가 갑자기 중심으로 재배치되었는지, 고도가 비정상적으로 낮은지, 속도와 body rate가 충분히 안정되었는지, physics time이 정상적으로 진행 중인지 같은 조건을 함께 살펴봐야 했다.
그래서 HoverPilot의 reset()은 단순히 연결만 열고 첫 상태를 반환하지 않는다. “학습을 시작해도 되는 상태인지”를 polling하면서 기다리는 과정이 들어간다.
def reset(self, *, seed=None, options=None):
...
self._client = self._client_factory()
self._client.connect()
ready_action = self._safe_start_action()
state, episode_start_reason = self._wait_for_ready_state(ready_action)
return self._start_episode_from_state(state, episode_start_reason=episode_start_reason)
이 과정이 필요한 이유는 reset()이 연결을 여는 일뿐 아니라, trainer의 수명주기까지 함께 책임져야 하기 때문이다.
step()에서 실제로 일어나는 일
step(action)은 Gymnasium 바깥에서는 짧지만, 내부에서는 여러 단계가 순서대로 실행된다.
- Gymnasium action을 RealFlight action으로 변환한다.
client.step()으로 입력을 보내고 최신 state를 받는다.- reward와 termination을 계산한다.
- trainer reset 여부와 에피소드 수명주기를 함께 정리한다.
- observation, reward,
terminated,truncated,info를 반환한다.
실제 구현의 핵심 부분은 아래와 같다.
def step(self, action: np.ndarray):
rf_action = gym_action_to_rf_action(action)
state = self._client.step(rf_action)
...
reward_breakdown = compute_reward(
state,
self.reward_config,
...,
)
termination = compute_termination(
state,
self.reward_config,
...,
)
observation = state_to_observation(state)
info = self._build_info(...)
return observation, float(reward_breakdown.reward), bool(termination.terminated), ..., info
중요한 점은 reward와 termination이 여기서 독립적으로 다시 호출된다는 것이다. 이전 글에서 만든 hover 기준이 이제 Gymnasium의 step() 안으로 들어오면서, 비로소 학습 알고리즘이 바로 사용할 수 있는 인터페이스가 된다.
info에 무엇을 담았나
강화학습 환경을 처음 만들 때 info를 대충 비워 두는 경우가 많다. 하지만 HoverPilot에서는 info가 꽤 중요하다. reward 하나만 보면 학습이 왜 망가지는지 알기 어렵기 때문이다.
그래서 step 결과의 info에는 다음과 같은 정보가 들어간다.
- reward breakdown
- termination reason
- 에피소드 수명주기
- state summary
- target hover 정보
이 정보는 학습 알고리즘 자체가 직접 쓰지는 않더라도, 디버깅과 reward 튜닝에서 큰 역할을 한다. 특히 boundary penalty가 너무 약한지, reset 이후 에피소드가 너무 늦게 시작되는지 같은 문제를 볼 때 유용하다.
Gymnasium 인터페이스가 주는 이점
이 단계가 끝나면 HoverPilot은 더 이상 “RealFlight를 조작하는 코드”에 머물지 않는다. 이제는 다음과 같은 성질을 갖게 된다.
- RL 라이브러리가 기대하는 표준 인터페이스를 따른다
- state, action, reward, termination이 한 객체 안에서 일관되게 묶인다
- 학습 루프와 시뮬레이터 통신 로직이 분리된다
- 다음 실험에서 PPO, SAC 같은 알고리즘을 바로 연결할 수 있다
즉 Gymnasium 환경으로 감싼다는 것은 단순한 포장 작업이 아니라, HoverPilot을 실험 가능한 강화학습 시스템으로 바꾸는 단계라고 볼 수 있다.
이번 단계의 결과
여기까지 오면 HoverPilot의 환경 계층은 최소한의 RL 인터페이스를 갖추게 된다.
reset()으로 에피소드 시작 상태를 얻을 수 있다step(action)으로 action 적용 결과를 반복적으로 받을 수 있다- observation은 12차원 벡터로 정리된다
- reward와 termination은 이전 단계의 설계를 그대로 사용한다
- reset 이후 다음 에피소드를 기다리는 수명주기까지 환경이 책임진다
이제 학습 코드 입장에서는 RealFlight Link의 세부 프로토콜을 알 필요가 없다. 그냥 Gymnasium 환경처럼 다루면 된다.
다음 단계
다음 글에서는 이 환경 위에 실제 학습 루프를 올린다. 그 순간부터 HoverPilot은 환경 정의를 끝낸 상태가 아니라, 정책을 학습시키고 성능을 비교할 수 있는 실험 단계로 넘어가게 된다.
함께 보기
- GitHub 저장소: hover-pilot
- 이번 글 기준 구현: gymnasium-interface