이전 글에서는 HoverPilot을 Gymnasium 환경과 호환되는 형태로 맞추었다. reset()과 step()이 있고, observation과 reward, termination도 연결되어 있다. 하지만 그 상태만으로는 아직 “PPO가 돌아간다”고 말하기는 어렵다.
실제로 학습 루프를 만들려면 여기에 정책 네트워크, 연속 action 샘플링, rollout 수집, advantage 계산, 정책 업데이트가 차례로 연결되어야 한다. 이번 글에서는 HoverPilot 관점에서 PPO가 어떤 부품들로 이루어져 있고, 각 부품이 학습 루프 안에서 어떤 역할을 하는지 정리한다.
왜 PPO인가
HoverPilot의 action은 네 개의 연속 제어값으로 이루어진다.
- aileron
- elevator
- throttle
- rudder
즉 이 문제는 본질적으로 연속 제어 문제다. DQN(Deep Q-Network)처럼 이산 action을 전제로 한 알고리즘은 바로 적용하기 어렵고, SAC(Soft Actor-Critic)나 TD3(Twin Delayed DDPG)는 장기적으로는 좋은 후보가 될 수 있지만 첫 구현에서 다루기에는 구현 요소가 너무 많다.
반면 PPO(Proximal Policy Optimization)는 첫 구현으로 시도해 볼 만하다. HoverPilot 입장에서 PPO는 다음과 같은 균형점에 있다.
- 연속 action을 Gaussian policy로 자연스럽게 다룰 수 있다
- actor-critic 구조가 비교적 단순하다
- rollout을 모으고 advantage를 계산한 뒤 바로 업데이트하는 흐름이 명확하다
- clipped objective 덕분에 정책이 한 번에 너무 크게 바뀌는 것을 막을 수 있다
HoverPilot의 현재 단계에서는 최고 효율보다 신뢰할 수 있는 초기 학습 루프를 만드는 것이 더 중요하다. 그 점에서 PPO는 꽤 실용적인 선택이다. 아래 그림처럼 PPO는 “호버 상태를 관찰하고, 조종 입력을 샘플링하고, 그 결과를 평가해 정책에 다시 반영하는 루프”로 볼 수 있다.
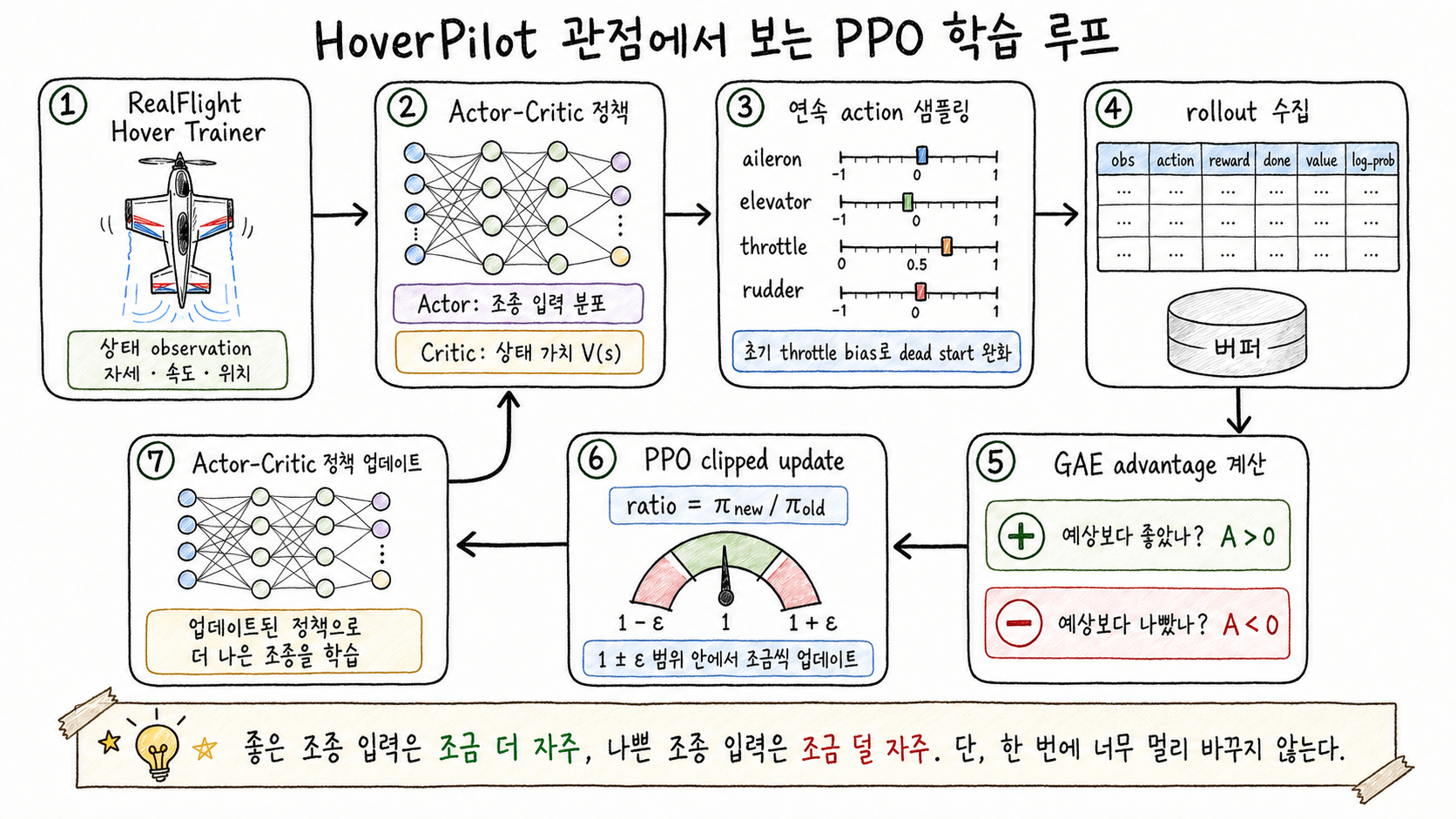
HoverPilot에서 PPO가 돌아가는 전체 흐름. 좋은 조종 입력은 조금 더 자주 선택하도록, 나쁜 조종 입력은 조금 덜 선택하도록 업데이트하되, Proximal이라는 이름처럼 한 번에 너무 멀리 바뀌지 않게 제한한다.
PPO 구현의 뼈대
한 줄로 말하면, 조종사(actor)와 평가자(critic)가 한 몸에 들어 있는 구조다. observation이 들어오면 actor는 “이 상황에서 어떤 입력을 낼까”를 결정하고, critic은 “지금 상황이 얼마나 괜찮은가”를 점수(value)로 매긴다.
HoverPilot에서는 이 둘을 같은 네트워크 안에 두고, 앞쪽의 shared MLP는 함께 쓴다. 그 뒤에서 한 갈래는 action 분포를 만드는 actor로, 다른 갈래는 상태 가치를 추정하는 critic으로 나뉜다.
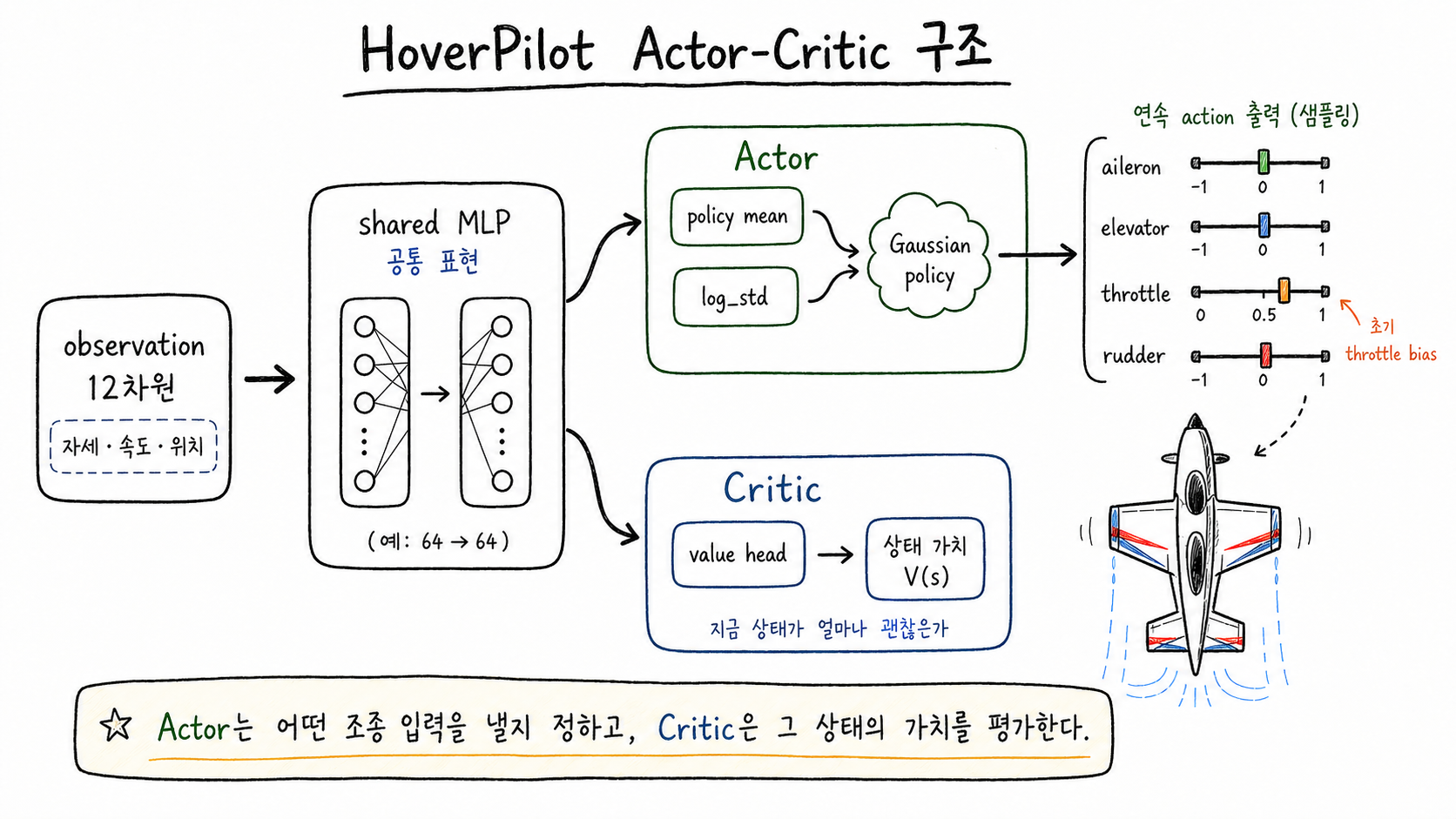
HoverPilot의 Actor-Critic 구조. observation에서 공통 표현을 만든 뒤, actor는 조종 입력 분포를 만들고 critic은 현재 상태의 value를 추정한다.
여기서 observation은 이미지가 아니라 12차원의 저차원 상태 벡터다. 그래서 처음부터 깊고 무거운 네트워크를 쓰기보다는, 공통 표현을 작게 만든 뒤 policy head와 value head로 나누는 단순한 구조로 시작했다. 이 구조는 성능을 극한까지 끌어올리기 위한 최종 형태라기보다, 환경과 학습 루프가 제대로 연결되는지 확인하기 좋은 baseline에 가깝다.
연속 action을 어떻게 다루나
한 줄로 말하면, 정책은 매번 action을 한 점으로 찍지 않고 “대략 이쯤에서 뽑겠다”는 분포를 만든다. actor는 네 개 조종 축에 대한 평균과 분산을 만들고, 그 정규분포에서 매 스텝 action을 샘플링한다.
이렇게 무작위성을 남겨두는 이유는 탐색 때문이다. 초기에 완전히 결정적인 정책으로 출발하면 같은 입력만 반복하게 되는데, 그러면 기체를 회복시키는 방향의 조종 입력은 영영 시도되지 않는다.
샘플링된 action은 그대로 쓰지 않고, RealFlight 쪽에서 허용하는 action space 범위 안으로 clip해서 적용한다. 아래 그림에서 중요한 흐름은 mean/std에서 action을 뽑고, 네 조종 채널로 나눈 뒤, 실제 환경에 넣기 전에 범위를 맞춘다는 점이다.
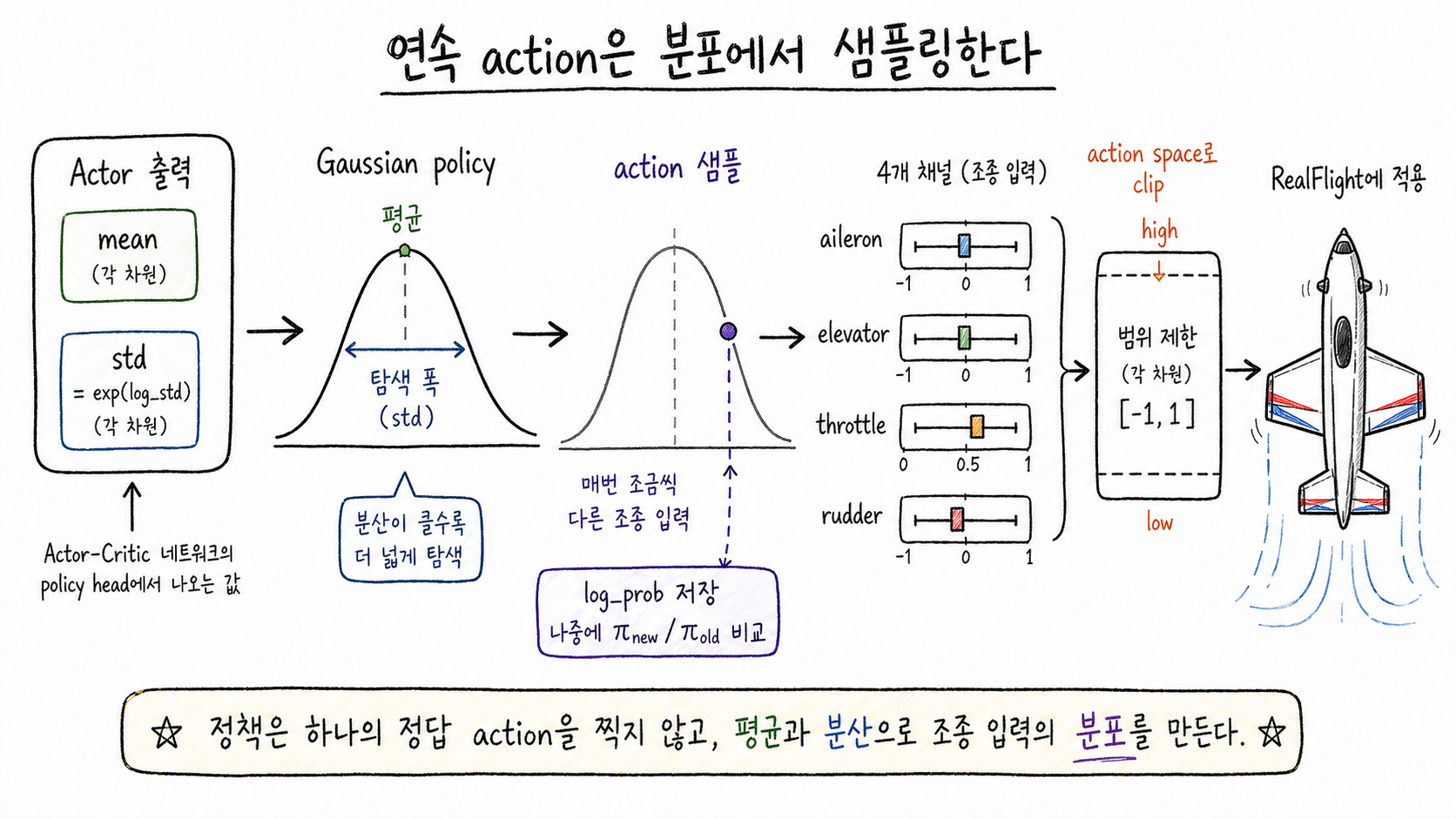
연속 action을 한 점으로 고정하지 않고 분포에서 샘플링하면, 초기 학습 중에도 다양한 조종 입력을 탐색할 수 있다. 단, 실제 적용 전에는 환경이 허용하는 범위 안으로 clip한다.
또 하나 저장해야 할 값이 log_prob다. PPO는 업데이트할 때 “rollout을 모을 당시의 정책이 이 action을 낼 확률”과 “현재 정책이 같은 action을 낼 확률”을 비교한다. 그래서 action 값만 저장하면 부족하고, 그 action이 당시 정책에서 얼마나 그럴듯했는지도 함께 저장해야 한다.
PPO는 경험을 어떻게 모으나
한 줄로 말하면, 현재 정책을 일정 시간 동안 굴려서 그동안의 경험을 한 묶음으로 저장한다. 이 묶음을 rollout(롤아웃, 정책이 한동안 굴러가면서 모은 경험 묶음)이라고 부른다.
DQN처럼 오래된 경험까지 다시 꺼내 쓰는 replay buffer를 두는 알고리즘과 달리, PPO는 짧은 길이의 최근 경험을 모아 업데이트하고 버린다. 그림으로 보면 현재 정책이 RealFlight에 action을 넣고, 환경에서 돌아온 결과를 timestep 순서대로 표에 쌓는 과정이다.
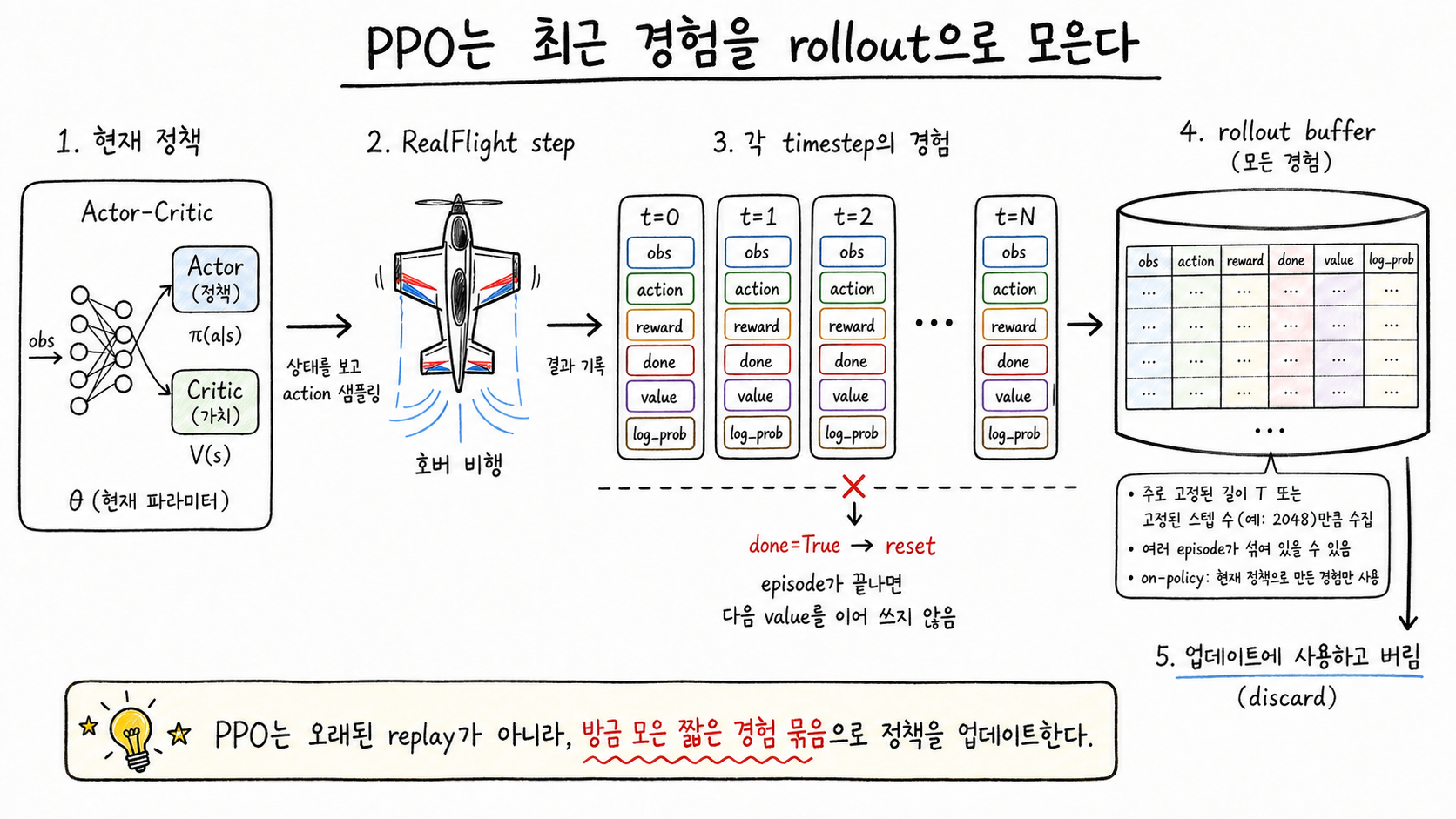
PPO는 오래된 경험을 계속 재사용하기보다, 현재 정책으로 방금 모은 짧은 rollout을 업데이트에 사용한다. 그래서 각 step의 action뿐 아니라 value와 log_prob도 함께 저장해야 한다.
rollout buffer에는 매 스텝의 observation, action, reward, episode가 끝났는지 표시하는 done, critic의 value 추정값, 그리고 그때의 log_prob를 같이 담는다. 여기서 done은 value bootstrap을 끊는 기준이 된다. episode가 끝난 시점부터는 다음 state의 value를 이어서 쓰면 안 되기 때문이다.
모은 경험에서 advantage를 어떻게 계산하나
한 줄로 말하면, “이 action은 critic의 예상보다 얼마나 좋았는가/나빴는가”를 점수로 환산한다. 이 점수가 advantage다. 양수면 예상보다 좋았다는 뜻이고, 음수면 예상보다 나빴다는 뜻이다.
actor 입장에서는 reward만 보는 것보다 “critic이 기대한 것에 비해 실제 결과가 어땠는가”가 더 직접적인 학습 신호가 된다. 예상보다 좋았다면 그 action은 더 자주 나오도록 밀어주고, 예상보다 나빴다면 덜 나오도록 낮춘다.
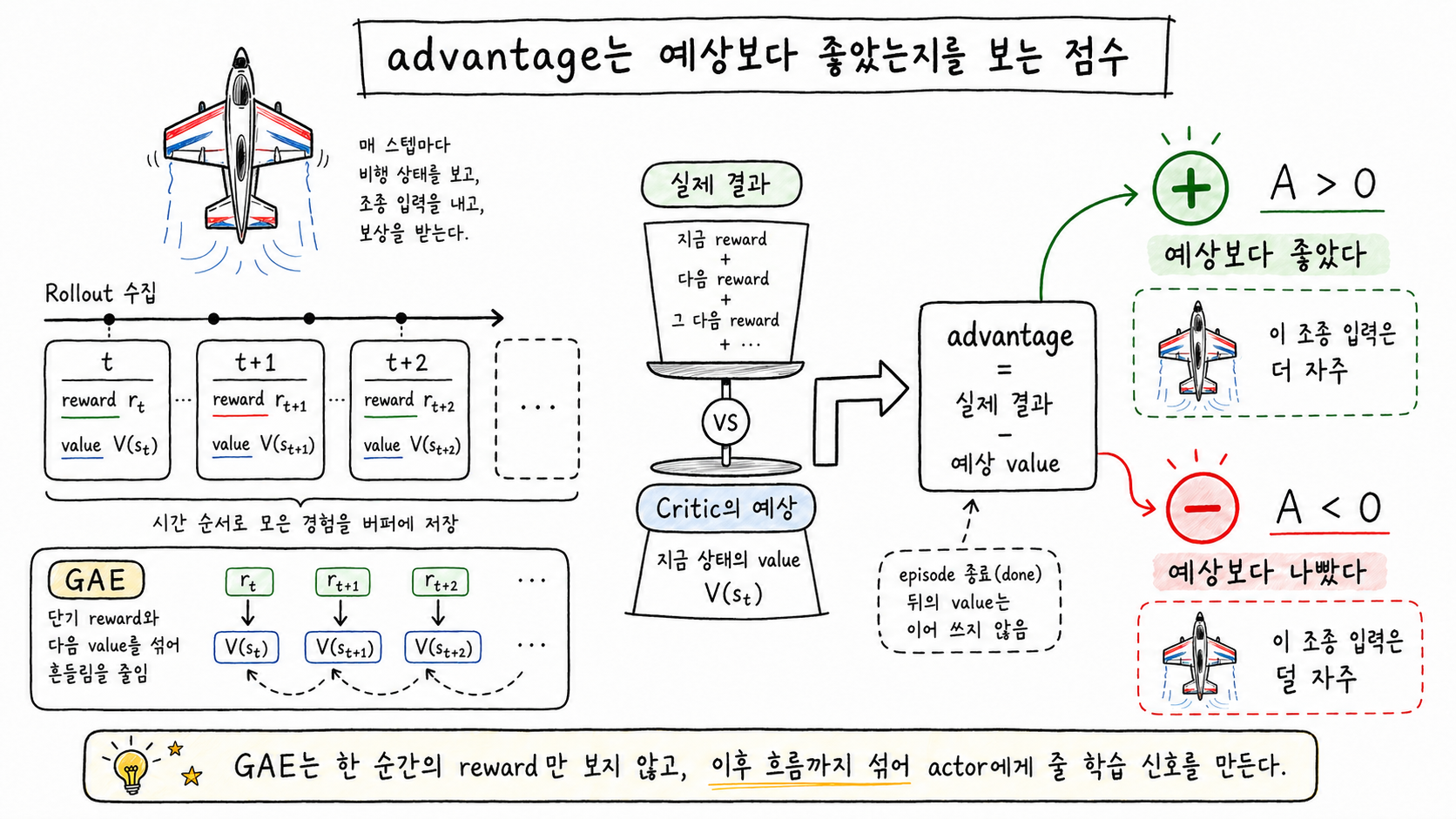
advantage는 critic의 예상보다 실제 결과가 얼마나 좋거나 나빴는지를 나타낸다. GAE는 한 순간의 reward만 보지 않고 이후 흐름과 value bootstrap을 함께 섞어 이 신호를 조금 더 안정적으로 만든다.
이 구현에서는 advantage 계산 방식으로 GAE(Generalized Advantage Estimation, 단기 보상과 장기 가치 추정을 섞어 평가하는 방법)를 쓴다. 받은 reward만 그대로 쓰는 것보다 신호의 흔들림(분산)이 작고, critic의 value 추정을 함께 활용할 수 있다는 장점이 있다. Hover처럼 한순간의 제어 실패가 몇 스텝 뒤의 추락으로 이어지는 문제에서는, 단기 reward만 보는 것보다 이런 방식이 더 낫다.
PPO는 정책을 얼마나 바꿀지 제한한다
한 줄로 말하면, 좋았던 action은 조금 더 자주, 나빴던 action은 조금 덜 자주 나오게 하되, 한 번에 너무 많이 바꾸지는 않는다.
업데이트할 때는 rollout을 모을 당시의 log_prob와 현재 정책에서 다시 계산한 log_prob를 비교한다. 이 비율이 ratio다. ratio가 1에 가까우면 정책이 거의 그대로라는 뜻이고, 1보다 크면 그 action을 더 자주 내는 방향으로 바뀌었다는 뜻이다.
여기에 advantage를 곱하면 학습 방향이 정해진다. A > 0이면 그 action의 확률을 높이고, A < 0이면 낮춘다. PPO의 핵심은 이 변화가 너무 커지지 않도록 ratio를 1 ± clip_epsilon 범위에서 제한하는 데 있다.
이 구현에서는 새로운 PPO 변형을 실험하기보다, 환경과 학습 루프가 일관되게 연결되는 baseline을 확보하는 데 집중했다.
첫술에 배가 차는가?
실행 테스트를 할 겸, PPO 훈련 루프를 돌려 보았다. 1,000 rollout 정도면 뭔가 변화가 보이지 않을까 기대했는데, 실제로는 그보다 훨씬 짧은 시간 안에 모델이 뭔가를 배우는 듯한 행동을 보여줬다. 다만, 내가 바라던 기동은 아니었다.
모델은 에피소드가 시작하자마자 비행기 꼬리부터 시작해서 지면에 살짝 착륙해버렸다. Airplane Hover Trainer에서 이러한 기동이 가능하다는 것도 처음 알았다. 이제 왜 이러한 방향으로 학습이 이루어지는 지 디버깅할 시간이다.
함께 보기
- GitHub 저장소: hover-pilot (태그: ppo-first-try)
- 참고 영상: Proximal Policy Optimization(PPO) - How to train Large Language Models