이전 글에서는 RealFlight Link를 통해 상태를 읽어올 수 있었다. 이제 한 단계 더 나아가서, 실제로 조종 신호(action)를 보내는 단계로 넘어간다. 이 단계를 통해 시스템은 단방향이 아니라, state와 action이 오가는 루프를 이루게 된다.
RealFlight Link는 양방향 인터페이스다
RealFlight Link의 핵심은 ExchangeData 요청이다. 이 요청은 단순히 상태를 받아오는 API가 아니다. 조금 더 정확히 말하면, 조종 입력을 보내고, 그 결과 상태를 받는 구조이다. 즉 하나의 ExchangeData 호출은
- 입력 (control signal) → 요청에 실어 보낸다
- 출력 (state) → 응답으로 돌려받는다
두 방향을 모두 포함한다.
InterLink 에뮬레이션 접근 방식
RealFlight는 InterLink DX 같은 전용 조종기를 기준으로 동작한다. HoverPilot은 물리적 실체가 없는 소프트웨어이기에 애석하게도 이 조종기를 조작할 방법이 없다. 다행히도 InterLink DX 대신에 소프트웨어 조종기로 조종 신호를 보내는 방법이 존재한다.
조금 더 간단하게 조종기 전체를 에뮬레이션하는 대신 InterLink가 보내는 채널 값을 소프트웨어로 직접 만들어 보내는 방식을 이용한다. 즉, 하드웨어를 흉내 내는 것이 아니라 채널 레벨의 동작을 코드로 에뮬레이션했다. 이 방식의 장점은 다음과 같다.
- 강화학습 action을 바로 연결할 수 있다
- 외부 입력 장치 없이 제어가 가능하다
- 구조가 단순하다
채널 매핑 (Channel Mapping)
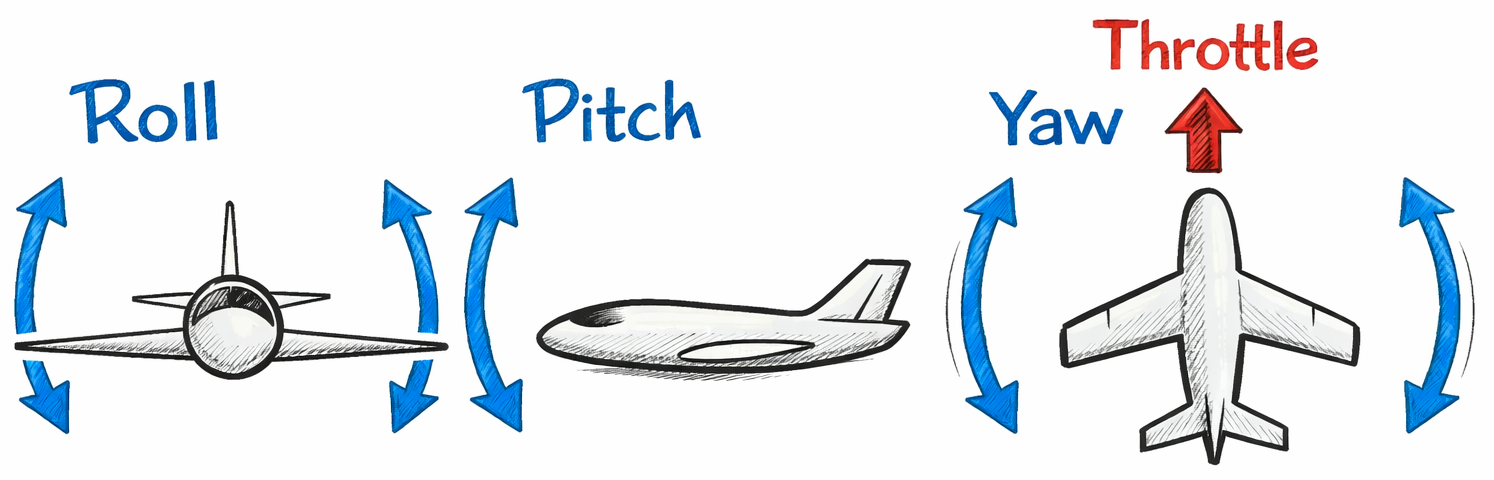
RealFlight는 12개의 채널을 사용한다. 하지만 우리가 실제로 다루는 건, 세 개의 조종면과 1개의 추력 제어에 필요한 4개 채널뿐이다. 각 조종면이 담당하는 기동은 다음과 같다.
- aileron (롤)
- elevator (피치)
- throttle (추력)
- rudder (요)
롤, 피치, 요가 의미하는 기동은 다음 그림을 통해 쉽게 파악할 수 있다.
코드에서는 다음과 같이 매핑했다. 시뮬레이터에서 각 채널별로 설정된 값에 따라 조종면을 매핑한다.
DEFAULT_CHANNEL_MAP = {
"aileron": 0,
"elevator": 1,
"throttle": 2,
"rudder": 3,
}
이렇게 해두면 기체나 설정이 바뀌는 경우에도 쉽게 수정할 수 있다.
action을 코드로 표현하기
RC 비행기를 조종하려면 실제로는 여러 개의 채널 값이 필요하다. 예를 들어 throttle, aileron 같은 값들이 각각 숫자로 전달된다. 그런데 이걸 바로 숫자로 다루면 코드의 의미 파악이 힘들다.
# 이런 식이면 의미 파악이 어렵다
[0.55, 0.0, 0.0, 0.0]
그래서 RFControlAction이라는 객체로 한 번 감싸서, 조종 입력을 논리적으로 표현한다. 이제 의미가 잘 드러난다.
action = RFControlAction(
throttle=0.55,
aileron=0.0,
elevator=0.0,
rudder=0.0,
)
그럼 실제로는 어떻게 전달될까? 시뮬레이터는 여전히 숫자 배열을 원한다. 그래서 마지막에 변환 과정을 한 번 거친다.
channels = action.to_channel_values()
이 과정에서 조종 입력은 이렇게 바뀐다.
[0.55, 0.0, 0.0, 0.0]
값 범위 처리
강화학습에서 사용하는 행동(action)의 값 범위와, RealFlight Link가 기대하는 입력 범위는 서로 다르다. 강화학습에서는 조종 입력을 대칭적인 범위로 다루는 것이 일반적이다.
- aileron / elevator / rudder → -1.0 ~ 1.0
- throttle → 0.0 ~ 1.0
특히 조종면은 “왼쪽 ↔ 오른쪽”, “위 ↔ 아래”처럼 중심(0)을 기준으로 양방향으로 움직이기 때문에, [-1, 1] 범위가 정책 학습에 더 자연스럽다.
하지만 RealFlight는 Link의 ExchangeData는 채널 값을 0.0에서 1.0까지만 허용한다. 그래서 내부적으로는 다음과 같은 변환을 거친다.
[-1, 1] → [0, 1]
즉, 에이전트는 학습하기 쉬운 형태([-1, 1])로 행동을 생성하고, 실제 시뮬레이터에는 호환되는 형태([0, 1])로 변환해서 전달하는 구조다.
실제 시그널 전송 구조
조종 신호는 ExchangeData 요청의 pControlInputs 안에 담겨 RealFlight Link로 전달한다. 즉, 우리가 만든 action 객체는 마지막 단계에서 채널 값 배열로 변환되고, 그 값이 XML에 실려 시뮬레이터로 전송된다. 예를 들어 “조종면은 중립으로 두고, 스로틀만 약간 올린 상태”는 아래처럼 표현할 수 있다.
<ExchangeData>
<pControlInputs>
<m-selectedChannels>4095</m-selectedChannels>
<m-channelValues-0to1>
<item>0.5000</item>
<item>0.5000</item>
<item>0.5500</item>
<item>0.5000</item>
...
</m-channelValues-0to1>
</pControlInputs>
</ExchangeData>
이 구조에서 반드시 지켜야 할 몇 가지 규칙이 있다.
- 채널 개수는 항상 12개여야 한다
- 모든 값은 0.0 ~ 1.0 범위여야 한다
- 순서가 바뀌면 완전히 다른 입력이 된다
step(action) 구조
조종 입력을 시뮬레이터에 보내고, 그 결과로 돌아온 최신 상태를 받아오는 과정이 다음 한 줄로 이루어진다.
state = client.step(action)
이 구조는 강화학습 환경에서 흔히 쓰는 인터페이스 형태를 유지한 것이다. 예를 들어 다음과 같은 형태다.
obs, reward, done, info = env.step(action)
추후 HoverPilot도 완전히 같은 구조를 보이겠지만, 현재 단계에서는 reward나 종료 조건 같은 요소는 아직 없기 때문에, 가장 핵심적인 부분만 남겨둔 형태다.
실행 루프
이제 앞에서 만든 step(action)을 반복해서 호출하면, 조종 신호를 계속 보내면서 기체가 어떻게 반응하는지 관찰할 수 있다. 가장 단순한 형태의 실행 루프는 아래와 같다.
while True:
state = client.step(action)
print(state.summary())
여기에 약간의 delay만 추가하면, 비행기가 입력에 따라 어떻게 반응하는 지 확인하기 쉬워진다.
time.sleep(0.1)
코드 확인
이 단계까지 구현한 코드는 아래 태그에서 확인할 수 있다.
- Repository: https://github.com/ruddyscent/hoverpilot
- Tag:
rflink-action-control
코드를 내려받으려면 아래처럼 체크아웃하면 된다.
git clone https://github.com/ruddyscent/hoverpilot.git
cd hoverpilot
git checkout rflink-action-control
여기까지 한 일
이제 RealFlight Link를 통해 조종 신호를 보내고, 그에 대한 상태 응답을 다시 받아오는 상호작용이 가능한 제어 루프의 출발점을 갖추게 됐다. 구체적으로 다음 요소들이 준비되었다.
- 상태(state) 읽기
- 조종 신호(action) 전송
- 채널 매핑 구성
- step 인터페이스 구현
다음 단계
지만 아직 강화학습 환경으로 바로 사용할 수 있는 상태는 아니다. 지금은 action을 보낼 수 있고 state를 받을 수도 있지만, 학습 루프를 구성하려면 그 사이를 이어주는 요소들이 더 필요하다. 다음으로 정리해야 할 것은 세 가지다.
- reward 설계
- observation 정의
- Gymnasium 환경 구성
reward는 에이전트가 어떤 행동을 좋은 것으로 배워야 하는지 알려주는 기준이 되고, observation은 정책이 어떤 상태 정보를 입력으로 사용할지 결정한다. 그리고 마지막으로 Gymnasium 환경까지 갖추면, 지금 만든 RealFlight Link 인터페이스를 강화학습 코드와 자연스럽게 연결할 수 있게 된다.